딥러닝 과정

ex) 학생이 문제집을 푸는 경우 가정
data: 책
model: 문제를 푸는 학생
logit: 문제를 푸는 과정
loss: 해답과 비교하는 과정
optm: 왜 틀렸는지 고쳐가는 과정
result: 계속 공부를 하면서 공부한 머리로 사회를 나간다 or 시험을 본다
이 과정의 반복
data
학습 시키기 위한 데이터
제일 중요한 부분
model
프로젝트의 성향에 따라서 어떤 모델을 쓸지 결정
Prediction / Logit
각 Class별로 예측한 값.
Loss / Cost
예측한 값과 정답과 비교해서 얼마나 틀렸는지를 확인.
이 Loss는 "얼마나 틀렸는지"를 말하며 이 값을 최대한 줄이는 것이 학습의 과정
Optimization
앞에서 얻은 Loss 값을 최소화하기 위해 기울기를 받아 최적화된 Variable 값들로 반환
Result
딥러닝 용어
layer: 어떻게 쌓냐 깊게 쌓냐
convolution: 합성곱, 특징을 뽑는 layer층, 이미지와 합성을 해서 어떠한 특징을 뽑아내는 것

weight/filter/kernel/variable/bias: 더 좋은 특징을 찾는 convolution을 찾기 위해 필터를 바꿔감. convolution 안에서 weight를 학습시킴
pooling layer: 피쳐를 뽑았으면 압축을 해줌. 거의 절반 크기로 줄임. 이미지가 가진 가장 큰 특징들을 가진 값들을 반으로 줄여준다. 압축이라고 생각
optimization: 인공지능을 학습을 시키고 나서 최적화
activation function: 앞에서 특징을 뽑아서 불필요한 것을 제거
softmax: 앞에서 받은 집합 값들을 확률로 나타내 주는 것
Cost / Loss / Loss Function: 얼마나 틀렸는지 검사

Learning Rate: 인공지능을 학습시킬 때 인간이 매번 조절해 줘야 됨 이중 하나
batch size: 많은 데이터 중에 몇 장을 줄 것인가
Epoch/Step: 전체 데이터를 한 번 봤을 때 1 에폭 에폭수만큼 반복
Train/Validation/Test: trainset과 testset으로 나눈다
Label/GroundTruth: 데이터에 대한 정답이 있어야 됨
anaconda 설치 완료
tensorflow 설치 완료

pytorch 설치 완료

아나콘다 단축키
shift+enter:실행하고 넘어감
alt+enter:실행하고 다음 줄을 생성하고 넘어감
ctrl+enter그 자리에 멈춤
파랑: command
초록: edit
d를 두 번 누르면 지워줄 수 있음
shift+m 셀 한 번에 묶을 수 있음
shift+crtl+-: 셀을 나눠줄 수 있음
kernel->restart->다시 일로 시작할 수 있음
run all: 한번에 다 실행
esc: command 부분 넘어감
esc+a: 위에 셀 생성
esc+b: 아래 셀 생성
markdown
메모를 할 수 있고 여러개의 글을 쓸 수 있음
Tensor
scalar 0차원
vector 선
matrix 면
tensor 입체, 3차원
numpy 고차원의 데이터를 다루기 위해 쉽게 만들어져 있음
np.shape: 모양을 나타냄
np.ndim: 차원의 개수/리스트를 씌우면 차원이 늘어남

하나를 넣었든 세 개를 넣었든 둘 다 1차원임
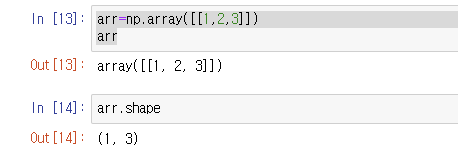
2차원이 됨, 하나가 세 개 모았다
numpy로는 4차원 이상도 표현 가능하다
4차원 예시

zeros&ones
0으로 채워진 numpy array를 만들 수 있음

1로 채워진 arr 만들 수 있음

arange로 0~8까지 숫자를 넣어준 뒤 이를 배열화를 할 수도 있음
arange+reshape

boolean indexing 예시

broadcast
연산하려는 서로 두 개의 행렬의 shape가 같지 않고 한쪽의 차원이라도 같거나 값의 갯수가 한 개일 때 이를 여러 복사를 하여 연산함


argmax=>몇 번째 인덱스가 제일 큰지
argmin=>몇 번째 인덱스가 제일 작은지
unique=>unique 한 값만 가지고 옴
dtype=>data type 볼 수 있음
astype=> datatype 변환 가능
random arry=np.random.randn 함수 사용

ravel=>arr의 차원을 1로 바꿔줌
np.expand_dims()=>안의 값은 유지하되 차원 수를 늘리고 싶을 때가 있음 이럴 때 사용하는 것이 expand_dims
//numpy2 기초 다시 한 번 듣기
시각화 기초
시각화 준비

점선 그래프

여러 그래프 그릴 준비

그래프 사이즈 조절
figure안에 figsize를 이용하여 가로 세로 길이 조절 가능
이름 달기
title
종합
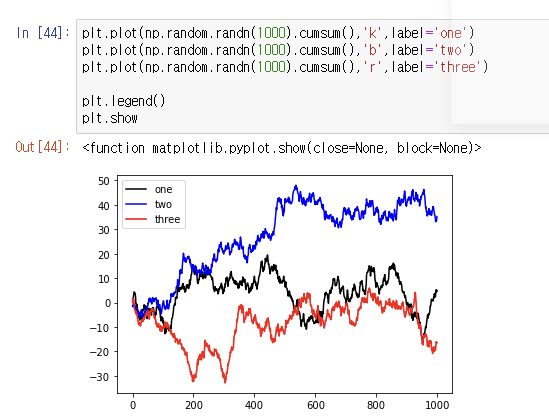
그래프 저장하기
plt.savefig
이미지 시각화
패키지 부르기

이미지 파일 열기

이미지 들여다보기
=>이미지를 열기 전에 shape 및 min max를 통해 이미지 range 필요
그림 나타내기

이미지 흑백으로 열기

colorbar 추가
plt.colorbar()
이미지 설정
plt.figsize
이미지에 제목 추가
plt.title
이미지 합치기 위해선 imshow를 두 사진을 해 주고 show를 넣어줌
alpha=0.5
투명도를 설정해 줘서 사진 합쳐줄 수 있음
TensorFlow
• 1.x에 비해 정말 쉬워졌음
• Numpy Array와 호환이 쉬움
• TensorBoard, TFLite, TPU
• 여전히 많은 사용자들이 사용
Pytorch
Dynamic Graph & Define by Run
• 쉽고 빠르며 파이써닉하다
• 어마어마한 성장률
tensorflow 사용
준비 단계

tensor 생성
constant라는 함수 사용해야 됨

shape 확인
data type 확인: data type에 따라 모델의 무게나 성능 차이에도 영향을 줄 수 있음

data type 변환
numpy에서 astype를 주었듯이
tensorflow에서는 tf.cast 사용

numpy로 불러줄 수도 있음
난수 생성
normal distribution은 중심극한에 의한 연속적인 모양
uniform distribution은 중심 극한 이론과는 무관하며 불연속적이며 일정한 분포
tensorflow에서는 정해줘야됨

data preprocess(MNIST)

데이터 불러오기

시각화해서 확인

train_y는 60000개인 것을 확인


OneHot Encoding
컴퓨터가 이해할 수 있는 형태로 변환하여 Label을 주도록 함

Feature Extraction
convolution
filters: layer에서 나갈 때 몇 개의 filter를 만들 것인지
kernel_size: filter의 사이즈
strides: 몇 개의 픽셀을 스킵하면서 훑어지나갈 것인지
padding: zero padding을 만들 것인지, VALID는 Padding이 없고 SAME은 Padding이 있음
activation: Activation Function을 만들것인지 당장 설정 안 해도 layer 층을 따로 만들 수 있음

weight 불러오기
layer.get_weights()
Fully Connected

Flatten
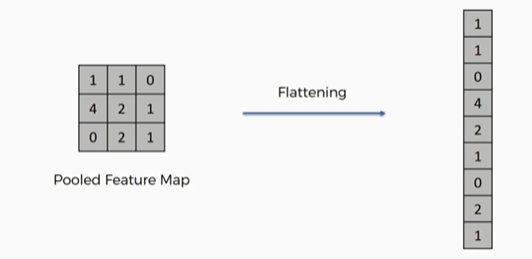

Dense




